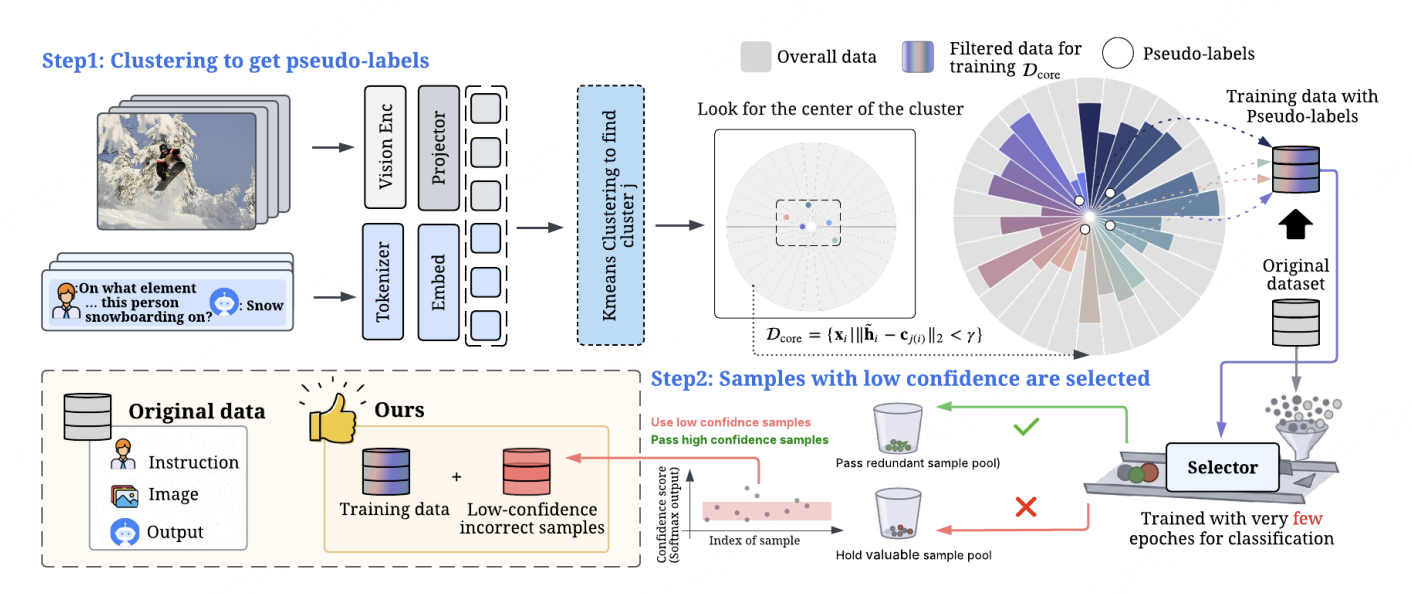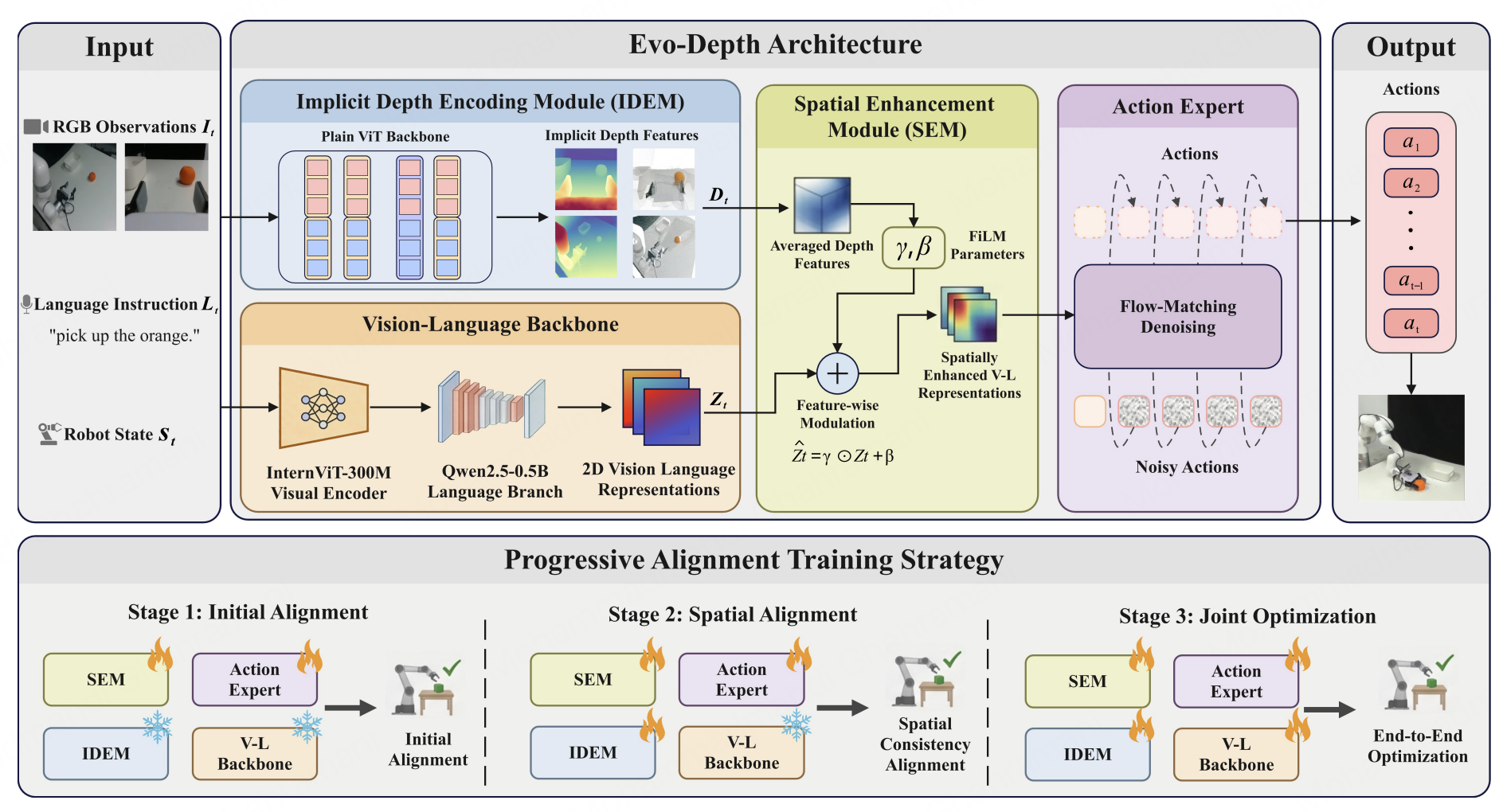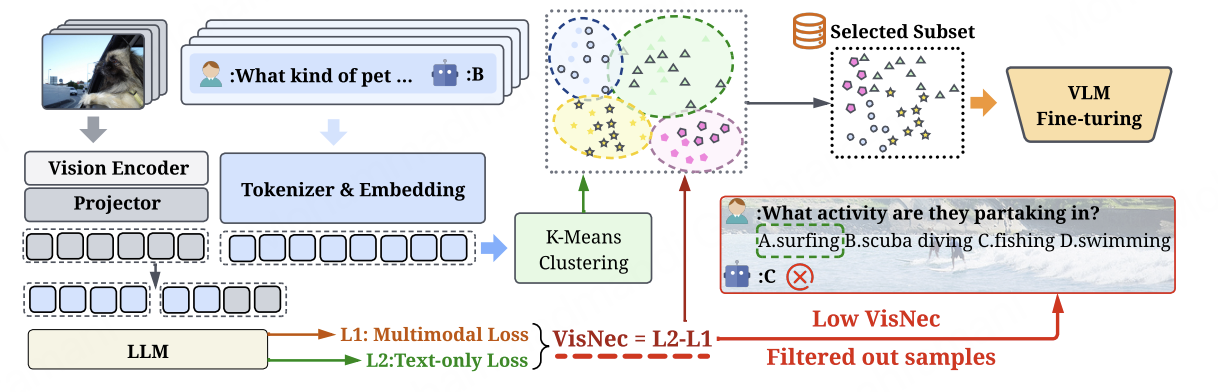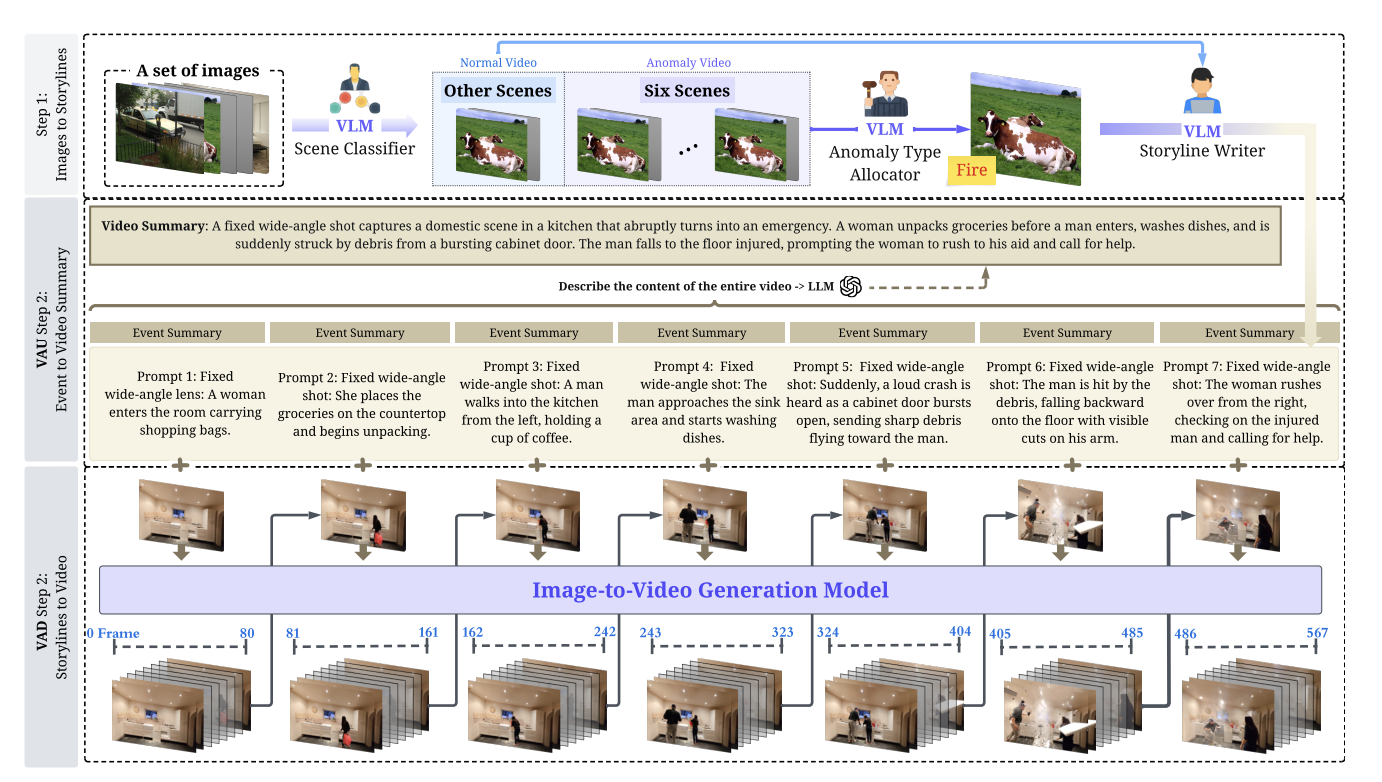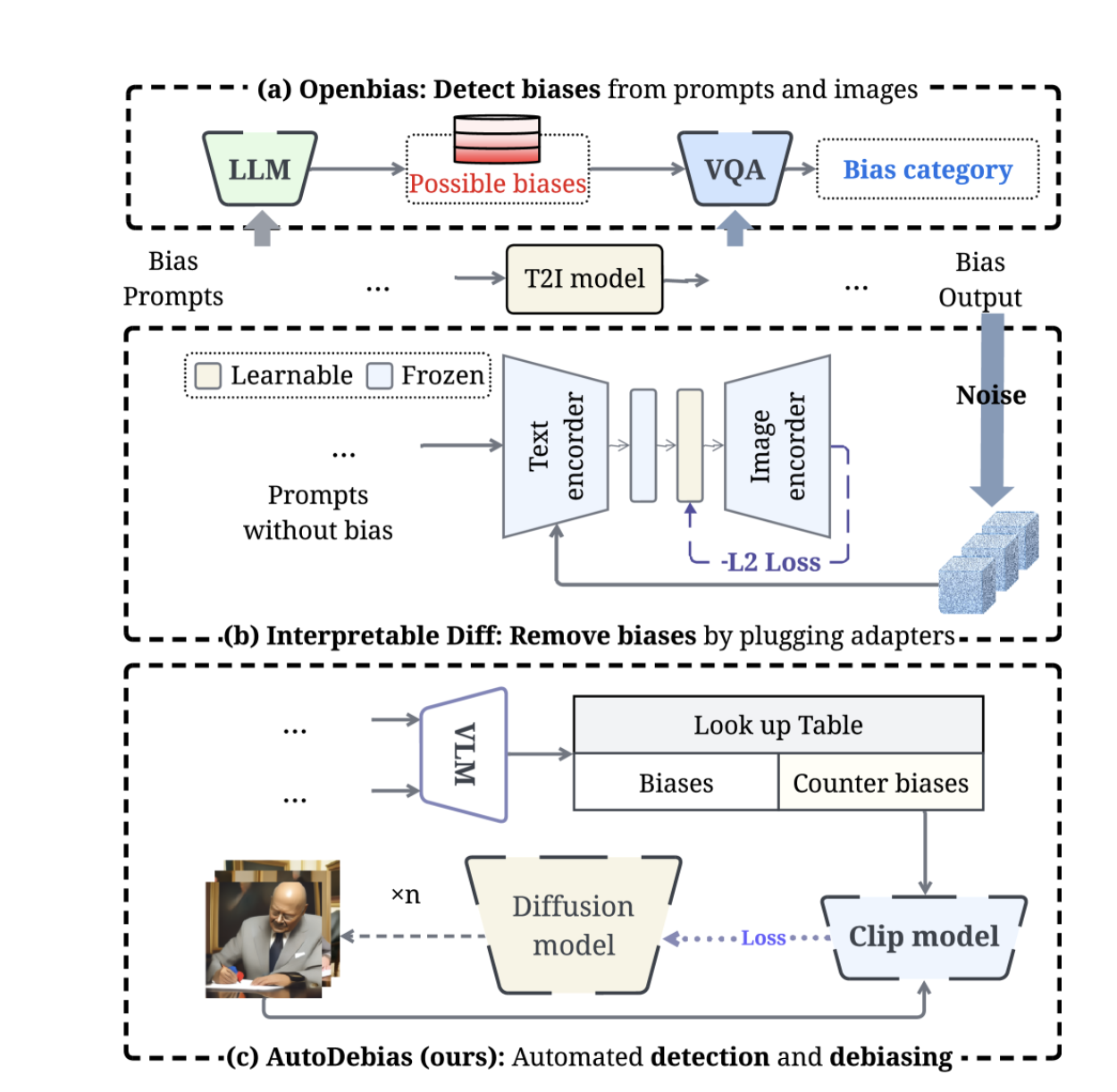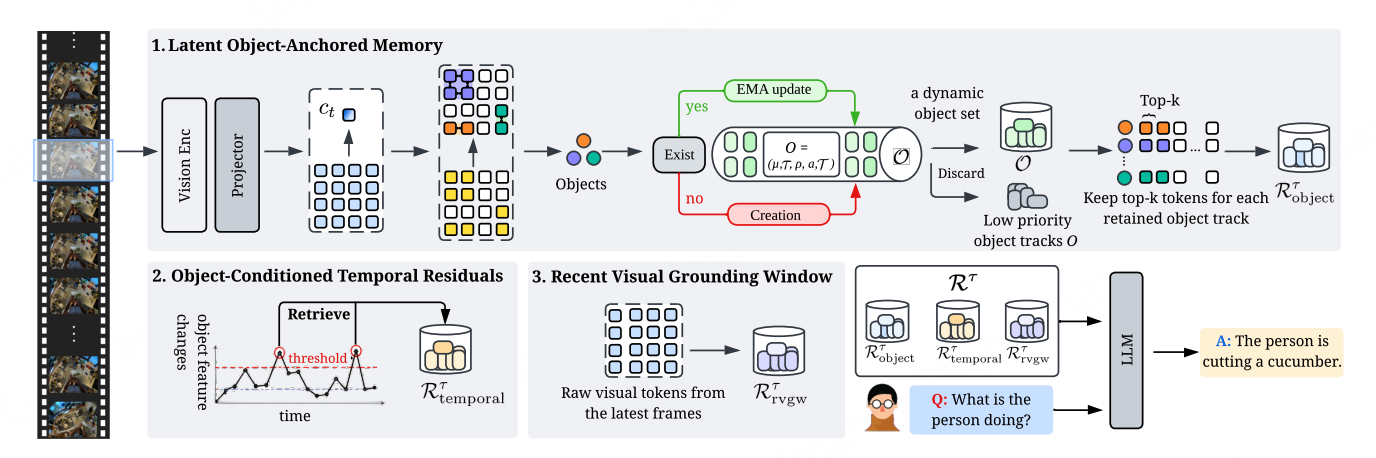
ObjectStream: Latent Objects as Memory Anchors for Streaming Video Understanding
Streaming video understanding requires models to retain useful visual evidence before future questions are known. ObjectStream is a training-free framework that treats latent objects as memory anchors: it induces spatially coherent object representations from frozen Video-LLM features, links them across frames into persistent anchors, and maintains bounded histories without external detectors or segmentation models. By preserving persistent object histories, transient object changes, and recent visual context, ObjectStream helps existing Video-LLMs reason over identities, interactions, and state changes more efficiently. Experiments show strong gains on online streaming and offline long-video benchmarks, including improved Qwen2.5-VL-7B performance on OVO-Bench while reducing peak GPU memory and TTFT by about 50%.